又是被自己菜醒的一天
背景
概况
- yolov3相对于v2的提升版本
- 使用dimeansion分簇来得到anchor boxes
- 每个框预测多标签的类别的时候使用2类的交叉熵作为损失函数
- 跨图像规模的预测,即隔一段时间resize输入图像的大小
- 特征提取网络结合了resNet的思想加入了shorcut,有53个卷积层。
方法
1. bounding box预测


其中tx,ty,tw,th分别为网络预测层输出的框(
的中心横坐标,纵坐标,框的宽度,框的高度,不对应该只是一个网络的输出并不是上述的含义,这个应该是借鉴faster RCNN的,等看了那篇论文再来解释,ok,上述第二图为解释tx,ty,tw,th的由来,截取自YOLOv2 论文笔记)作者这边不是用的这个方法计算的框的x和y,而是预测相对网格cell的位置,并且通过逻辑斯蒂归一化;pw,ph为先验框(anchor boxes)的宽度和高度;cx,cy为预测中心点所在cell相对图片左上角点的偏移;通过上图公式将预测输出最终转换为框的中心点左边bx,by,框的宽度和高度bw,bh如果一个先验框并不是最好的但是其覆盖ground true超过一定阈值,论文中取的是0.5,则忽略这个预测结果且不计算进损失中
2. 类预测
- 每个框可能需要预测包含多标签的类,论文中没使用softmax而是用的独立的逻辑斯蒂分类。因为使用softmax的前提假设是一个框中只包含一个类,而现实情况并不是这样的。
3. box的跨尺度预测(针对之前yolo小目标检测不到的诟病)
yolov3在三个尺度上做预测
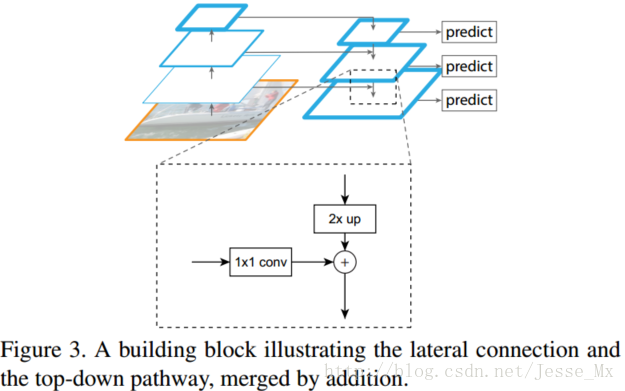
参考的FPN(特征金字塔)网络,下图引自FPN最新的目标检测算法。每种尺度预测三个box,anchor的设计方式仍然使用聚类的方法得到9 个聚类中心,再将其按照大小均分给3种尺度。尺度1:在基础网络之后添加一些卷积层再输出box信息;尺度2:从尺度1中的倒数第二层的卷积层上采样再与最后一个16×16大小的特征图相加,再次通过多个卷积层后输出box信息,相比尺度1变大两倍;尺度3:与尺度2类似使用了32×32大小的特征图。可以参考网络结构定义文件yolov3.cfg。
把高层特征做2倍上采样(最邻近上采样法),然后将其和对应的前一层特征结合(前一层要经过1 * 1的卷积核才能用,目的是改变channels,应该是要和后一层的channels相同),结合方式就是做像素间的加法。重复迭代该过程,直至生成最精细的特征图。
论文使用kmean获得先验anchor boxes
4. 特征提取
- Darknet53,53个卷积层,加上shorcut,下图为其网络结构

5. 训练
- 训练方法和yolov2相同,多尺度(隔一段epoch改变输入的图片大小,有小有大),BN等
性能及总结
性能

总结
- 改进后的yolov3能够更好的检测小目标(引入了跨尺度预测),但是相对的中中等及大尺寸的目标效果有所降低
- 其他都很好哇,666